Oracle Pipelined Table Functions | |
Overview
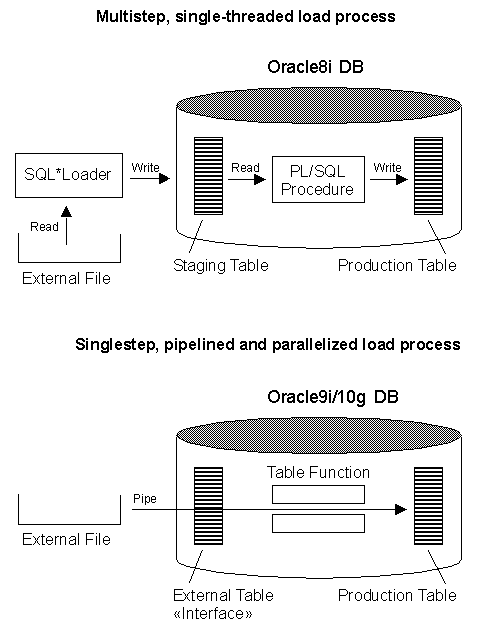 | |
Simple Example - Generating Some Random Data
Typical Pipelined Example
Conclusion
| |
Wednesday, 26 September 2018
Oracle Pipelined Table Functions
Monday, 24 September 2018
PL/SQL Autonomous Transaction Tips
Question: What is the idea of an automous transaction in PL/SQL? I understand that there is the pragma automous transaction but I am unclear about when to use automous transactions.
Answer: Autonomous transactions are used when you wan to roll-back some code while continuing to process an error logging procedure.
The term "automous transaction" refers to the ability of PL/SQL temporarily suspend the current transaction and begin another, fully independent transaction (which will not be rolled-back if the outer code aborts). The second transaction is known as an autonomous transaction. The autonomous transaction functions independently from the parent code.
An autonomous transaction has the following characteristics:

There are many times when you might want to use an autonomous transaction to commit or roll back some changes to a table independently of a primary transaction's final outcome.
We use a compiler directive in PL/SQL (called a pragma) to tell Oracle that our transaction is autonomous. An autonomous transaction executes within an autonomous scope. The PL/SQL compiler is instructed to mark a routine as autonomous (i.e. independent) by the AUTONMOUS_TRANSACTIONS pragma from the calling code.
As an example of autonomous transactions, let's assume that you need to log errors into a Oracle database log table. You need to roll back the core transaction because of the resulting error, but you don't want the error log code to rollback. Here is an example of a PL/SQL error log table used as an automous transaction:



As we can see, the error is logged in the autonomous transaction, but the main transaction is rolled back.
Thursday, 20 September 2018
Oracle PL/SQL Collections: Varrays, Nested & Index by Tables
What is Collection?
A Collection is an ordered group of elements of particular data types. It can be a collection of simple data type or complex data type (like user-defined or record types).
In the collection, each element is identified by a term called "subscript." Each item in the collection is assigned with a unique subscript. The data in that collection can be manipulated or fetched by referring to that unique subscript.
Collections are most useful things when a large data of the same type need to be processed or manipulated. Collections can be populated and manipulated as whole using 'BULK' option in Oracle.
In this tutorial, you will learn-
- What is Collection?
- Varrays
- Nested Tables
- Index-by-table
- Constructor and Initialization Concept in Collections
- Collection Methods
Collections are classified based on the structure, subscript, and storage as shown below.
- Index-by-tables (also known as Associative Array)
- Nested tables
- Varrays
At any point, data in the collection can be referred by three terms Collection name, Subscript, Field/Column name as "<collection_name>(<subscript>).<column_name>". You are going to learn about these above-mentioned collection categories further in the below section.
Varrays
Varray is a collection method in which the size of the array is fixed. The array size cannot be exceeded than its fixed value. The subscript of the Varray is of a numeric value. Following are the attributes of Varrays.
- Upper limit size is fixed
- Populated sequentially starting with the subscript '1'
- This collection type is always dense, i.e. we cannot delete any array elements. Varray can be deleted as a whole, or it can be trimmed from the end.
- Since it always is dense in nature, it has very less flexibility.
- It is more appropriate to use when the array size is known and to perform similar activities on all the array elements.
- The subscript and sequence always remain stable, i.e. the subscript and count of the collection is always same.
- They need to be initialized before using them in programs. Any operation (except EXISTS operation) on an uninitialized collection will throw an error.
- It can be created as a database object, which is visible throughout the database or inside the subprogram, which can be used only in that subprogram.
The below figure will explain the memory allocation of Varray (dense) diagrammatically.
| Subscript | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Value | Xyz | Dfv | Sde | Cxs | Vbc | Nhu | Qwe |
Syntax for VARRAY:
TYPE <type_name> IS VARRAY (<SIZE>) OF <DATA_TYPE>;
- In the above syntax, type_name is declared as VARRAY of the type 'DATA_TYPE' for the given size limit. The data type can be either simple or complex type.
Nested Tables
A Nested table is a collection in which the size of the array is not fixed. It has the numeric subscript type. Below are more descriptions about nested table type.
- The Nested table has no upper size limit.
- Since the upper size limit is not fixed, the collection, memory needs to be extended each time before we use it. We can extend the collection using 'EXTEND' keyword.
- Populated sequentially starting with the subscript '1'.
- This collection type can be of both dense and sparse, i.e. we can create the collection as a dense, and we can also delete the individual array element randomly, which make it as sparse.
- It gives more flexibility regarding deleting the array element.
- It is stored in the system generated database table and can be used in the select query to fetch the values.
- The subscript and sequence are not stable, i.e. the subscript and the count of the array element can vary.
- They need to be initialized before using them in programs. Any operation (except EXISTS operation) on the uninitialized collection will throw an error.
- It can be created as a database object, which is visible throughout the database or inside the subprogram, which can be used only in that subprogram.
The below figure will explain the memory allocation of Nested Table (dense and sparse) diagrammatically. The black colored element space denotes the empty element in a collection i.e. sparse.
| Subscript | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Value (dense) | Xyz | Dfv | Sde | Cxs | Vbc | Nhu | Qwe |
| Value(sparse) | Qwe | Asd | Afg | Asd | Wer |
Syntax for Nested Table:
TYPE <tvpe name> IS TABLE OF <DATA TYPE>;
- In the above syntax, type_name is declared as Nested table collection of the type 'DATA_TYPE'. The data type can be either simple or complex type.
Index-by-table
Index-by-table is a collection in which the array size is not fixed. Unlike the other collection types, in the index-by-table collection the subscript can consist be defined by the user. Following are the attributes of index-by-table.
- The subscript can of integer or strings. At the time of creating the collection, the subscript type should be mentioned.
- These collections are not stored sequentially.
- They are always sparse in nature.
- The array size is not fixed.
- They cannot be stored in the database column. They shall be created and used in any program in that particular session.
- They give more flexibility in terms of maintaining subscript.
- The subscripts can be of negative subscript sequence also.
- They are more appropriate to use for relatively smaller collective values in which the collection can be initialized and used within the same subprograms.
- They need not be initialized before start using them.
- It cannot be created as a database object. It can only be created inside the subprogram, which can be used only in that subprogram.
- BULK COLLECT cannot be used in this collection type as the subscript should be given explicitly for each record in the collection.
The below figure will explain the memory allocation of Nested Table (sparse) diagrammatically. The black colored element space denotes the empty element in a collection i.e. sparse.
| Subscript (varchar) | FIRST | SECOND | THIRD | FOURTH | FIFTH | SIXTH | SEVENTH |
| Value(sparse) | Qwe | Asd | Afg | Asd | Wer |
Syntax for Index-by-Table
TYPE <type_name> IS TABLE OF <DATA_TYPE> INDEX BY YARCHAR2 (10);
- In the above syntax, type_name is declared as an index-by-table collection of the type 'DATA_TYPE'. The data type can be either simple or complex type. The subsciprt/index variable is given as VARCHAR2 type with maximum size as 10.
Constructor and Initialization Concept in Collections
Constructors are the in-built function provided by the oracle that has the same name as of the object or collections. They are executed first whenever object or collections are getting referred for the first time in a session. Below are the important details of constructor in collection context:
- For collections, these constructors should be called explicitly to initialize it.
- Both Varray and Nested tables need to be initialized through these constructors before getting referred into the program.
- Constructor implicitly extends the memory allocation for a collection (except Varray), hence constructor can also assign the variables to the collections.
- Assigning values to the collection through constructors will never make the collection sparse.
Collection Methods
Oracle provides many functions to manipulate and to work with the collections. These functions are very much useful in the program to determine and to modify the different attribute of the collections. The Following table will give the different functions and their description.
| Method | Description | SYNTAX |
| EXISTS (n) | This method will return Boolean results. It will return 'TRUE' if the nthelement exists in that collection, else it will return FALSE. Only EXISTS functions can be used in uninitialized collection | <collection_name>.EXISTS(element_position) |
| COUNT | Gives the total count of the elements present in a collection | <collection_name>.COUNT |
| LIMIT | It returns the maximum size of the collection. For Varray, it will return the fixed size that has been defined. For Nested table and Index-by-table, it gives NULL | <collection_name>.LIMIT |
| FIRST | Returns the value of the first index variable(subscript) of the collections | <collection_name>.FIRST |
| LAST | Returns the value of the last index variable(subscript) of the collections | <collection_name>.LAST |
| PRIOR (n) | Returns precedes index variable in a collection of the nth element. If there is no precedes index value NULL is returned | <collection_name>.PRIOR(n) |
| NEXT (n) | Returns succeeds index variable in a collection of the nth element. If there is no succeeds index value NULL is returned | <collection_name>.NEXT(n) |
| EXTEND | Extends one element in a collection at the end | <collection_name>.EXTEND |
| EXTEND (n) | Extends n elements at the end of a collection | <collection_name>.EXTEND(n) |
| EXTEND (n,i) | Extends n copies of the ith element at the end of the collection | <collection_name>.EXTEND(n,i) |
| TRIM | Removes one element from the end of the collection | <collection_name>.TRIM |
| TRIM (n) | Removes n elements from the end of collection | <collection_name>.TRIM (n) |
| DELETE | Deletes all the elements from the collection. Makes the collection empty | <collection_name>.DELETE |
| DELETE (n) | Deletes the nth element from the collection. If the nth element is NULL, then this will do nothing | <collection_name>.DELETE(n) |
| DELETE (m,n) | Deletes the element in the range mthto nth in the collection | <collection_name>.DELETE(m,n) |
Example1: Record Type at Subprogram level
In this example, we are going to see how to populate the collection using 'BULK COLLECT' and how to refer the collection data.

DECLARE
TYPE emp_det IS RECORD
(
EMP_NO NUMBER,
EMP_NAME VARCHAR2(150),
MANAGER NUMBER,
SALARY NUMBER
);
TYPE emp_det_tbl IS TABLE OF emp_det; guru99_emp_rec emp_det_tbl:= emp_det_tbl();
BEGIN
INSERT INTO emp (emp_no,emp_name, salary, manager) VALUES (1000,’AAA’,25000,1000);
INSERT INTO emp (emp_no,emp_name, salary, manager) VALUES (1001,'XXX’,10000,1000);
INSERT INTO emp (emp_no, emp_name, salary, manager) VALUES (1002,'YYY',15000,1000);
INSERT INTO emp (emp_no,emp_name,salary, manager) VALUES (1003,’ZZZ’,'7500,1000);
COMMIT:
SELECT emp no,emp_name,manager,salary BULK COLLECT INTO guru99_emp_rec
FROM emp;
dbms_output.put_line (‘Employee Detail');
FOR i IN guru99_emp_rec.FIRST..guru99_emp_rec.LAST
LOOP
dbms_output.put_line (‘Employee Number: '||guru99_emp_rec(i).emp_no);
dbms_output.put_line (‘Employee Name: '||guru99_emp_rec(i).emp_name);
dbms_output.put_line (‘Employee Salary:'|| guru99_emp_rec(i).salary);
dbms_output.put_line(‘Employee Manager Number:'||guru99_emp_rec(i).manager);
dbms_output.put_line('--------------------------------');
END LOOP;
END;
/
Code Explanation:
- Code line 2-8: Record type 'emp_det' is declared with columns emp_no, emp_name, salary and manager of data type NUMBER, VARCHAR2, NUMBER, NUMBER.
- Code line 9: Creating the collection 'emp_det_tbl' of record type element 'emp_det'
- Code line 10: Declaring the variable 'guru99_emp_rec' as 'emp_det_tbl' type and initialized with null constructor.
- Code line 12-15: Inserting the sample data into the 'emp' table.
- Code line 16: Committing the insert transaction.
- Code line 17: Fetching the records from 'emp' table and populating the collection variable as a bulk using the command "BULK COLLECT". Now the variable 'guru99_emp_rec' contains all the record that are present in the table 'emp'.
- Code line 19-26: Setting the 'FOR' loop using to print all the records in the collection one-by-one. The collection method FIRST and LAST is used as lower and higher limit of the loop.
Output: As you can see in the above screenshot when the above code is executed you will get the following output
Employee Detail Employee Number: 1000 Employee Name: AAA Employee Salary: 25000 Employee Manager Number: 1000 ---------------------------------------------- Employee Number: 1001 Employee Name: XXX Employee Salary: 10000 Employee Manager Number: 1000 ---------------------------------------------- Employee Number: 1002 Employee Name: YYY Employee Salary: 15000 Employee Manager Number: 1000 ---------------------------------------------- Employee Number: 1003 Employee Name: ZZZ Employee Salary: 7500 Employee Manager Number: 1000 ----------------------------------------------
Friday, 13 July 2018
PL/SQL Autonomous Transaction Tips
Question: What is the idea of an automous transaction in PL/SQL? I understand that there is the pragma automous transaction but I am unclear about when to use automous transactions.
Answer: Autonomous transactions are used when you wan to roll-back some code while continuing to process an error logging procedure.
The term "automous transaction" refers to the ability of PL/SQL temporarily suspend the current transaction and begin another, fully independent transaction (which will not be rolled-back if the outer code aborts). The second transaction is known as an autonomous transaction. The autonomous transaction functions independently from the parent code.
An autonomous transaction has the following characteristics:
There are many times when you might want to use an autonomous transaction to commit or roll back some changes to a table independently of a primary transaction's final outcome.
We use a compiler directive in PL/SQL (called a pragma) to tell Oracle that our transaction is autonomous. An autonomous transaction executes within an autonomous scope. The PL/SQL compiler is instructed to mark a routine as autonomous (i.e. independent) by the AUTONMOUS_TRANSACTIONS pragma from the calling code.
As an example of autonomous transactions, let's assume that you need to log errors into a Oracle database log table. You need to roll back the core transaction because of the resulting error, but you don't want the error log code to rollback. Here is an example of a PL/SQL error log table used as an automous transaction:
As we can see, the error is logged in the autonomous transaction, but the main transaction is rolled back.
Thursday, 21 June 2018
Executing a DB package at Bean with a return value by using HashMap
Executing a package with a return value.
public HashMap getProductPrice(String compcode, String unitcode, String prodCode, Date invDate) {
BindingContext bindingContext = BindingContext.getCurrent();
DCDataControl dc = bindingContext.findDataControl("AppModuleAMDataControl");
AppModuleAMImpl appM = (AppModuleAMImpl)dc.getDataProvider();
System.out.println("**Price from ValueChange:"+compcode+" "+unitcode+" prodCode:"+prodCode);
String sqlproc2 = "{? = call Pos_Inv_Validation_Pkg.Get_Price(?,?,?,sysdate,?,?)}";
//pi_vchno_pkg.get_pr_vchno
CallableStatement sqlProcStmt2 = appM.getDBTransaction().createCallableStatement(sqlproc2, 0);
HashMap hm = new HashMap<String, Object>();
try {
sqlProcStmt2.registerOutParameter(1, Types.VARCHAR);
sqlProcStmt2.setString(2, compcode);
sqlProcStmt2.setString(3, unitcode);
sqlProcStmt2.setString(4, prodCode);
//sqlProcStmt2.setDate(5, invDate.dateValue());
sqlProcStmt2.registerOutParameter(5, java.sql.Types.VARCHAR);
sqlProcStmt2.registerOutParameter(6, java.sql.Types.INTEGER);
sqlProcStmt2.execute();
BigDecimal v_ret_val = sqlProcStmt2.getBigDecimal(1);
String priceType = sqlProcStmt2.getString(5);
BigDecimal priceCntrlNo = sqlProcStmt2.getBigDecimal(6);
hm.put("price", v_ret_val);
hm.put("priceType", priceType);
hm.put("priceCntrlNo", priceCntrlNo);
System.out.println("v_ret_val " + v_ret_val+" --Date: "+invDate.dateValue()+" priceCntrlNo :"+priceCntrlNo+":priceType"+priceType);
} catch (SQLException e) {
System.out.println(e.getMessage());
}
return hm;
}
public HashMap getProductPrice(String compcode, String unitcode, String prodCode, Date invDate) {
BindingContext bindingContext = BindingContext.getCurrent();
DCDataControl dc = bindingContext.findDataControl("AppModuleAMDataControl");
AppModuleAMImpl appM = (AppModuleAMImpl)dc.getDataProvider();
System.out.println("**Price from ValueChange:"+compcode+" "+unitcode+" prodCode:"+prodCode);
String sqlproc2 = "{? = call Pos_Inv_Validation_Pkg.Get_Price(?,?,?,sysdate,?,?)}";
//pi_vchno_pkg.get_pr_vchno
CallableStatement sqlProcStmt2 = appM.getDBTransaction().createCallableStatement(sqlproc2, 0);
HashMap hm = new HashMap<String, Object>();
try {
sqlProcStmt2.registerOutParameter(1, Types.VARCHAR);
sqlProcStmt2.setString(2, compcode);
sqlProcStmt2.setString(3, unitcode);
sqlProcStmt2.setString(4, prodCode);
//sqlProcStmt2.setDate(5, invDate.dateValue());
sqlProcStmt2.registerOutParameter(5, java.sql.Types.VARCHAR);
sqlProcStmt2.registerOutParameter(6, java.sql.Types.INTEGER);
sqlProcStmt2.execute();
BigDecimal v_ret_val = sqlProcStmt2.getBigDecimal(1);
String priceType = sqlProcStmt2.getString(5);
BigDecimal priceCntrlNo = sqlProcStmt2.getBigDecimal(6);
hm.put("price", v_ret_val);
hm.put("priceType", priceType);
hm.put("priceCntrlNo", priceCntrlNo);
System.out.println("v_ret_val " + v_ret_val+" --Date: "+invDate.dateValue()+" priceCntrlNo :"+priceCntrlNo+":priceType"+priceType);
} catch (SQLException e) {
System.out.println(e.getMessage());
}
return hm;
}
Sunday, 17 June 2018
Difference between 10g, 11g and 12c
Difference between 10g, 11g and 12c
Oracle Database 10g New Features:
NID utility has been introduced to change the database name and id.
Automated Storage Management (ASM). ASMB, RBAL, ARBx are the new background processes related to ASM.
New memory structure in SGA i.e. Streams pool (streams_pool_size parameter), useful for datapump activities & streams replication.
From Oracle 10g, the spool command can append to an existing one.
SQL> spool result.log append
Ability to rename tablespaces (except SYSTEM and SYSAUX), whether permanent or temporary, using the following command:
SQL> ALTER TABLESPACE oldname RENAME TO newname;
Oracle Database 11g New Features:
Ability to mark a table as read only.
SQL> alter table table-name read only;
Temporary tablespace or it's tempfile can be shrinked, up to specified size.
SQL> alter tablespace temp-tbs shrink space;
SQL> alter tablespace temp-tbs shrink space keep n{K|M|G|T|P|E};
Introduction of ADR, single location of all error and trace data in the database, diagnostic_dump parameter
A new parameter is added in 11g, called MEMORY_TARGET, automatic memory management for both the SGA and PGA.
A system privelege is introduced in 11g called SYSASM, and this is granted to users who need to perform ASM related tasks.
Oracle Database 12c New Features:
Moving and Renaming datafile is now ONLINE, no need to put datafile in offline.
SQL> alter database move datafile 'path' to 'new_path';
No need to shutdown database for changing archive log mode.
Like sysdba, sysoper & sysasm, we have new privileges, in Oracle 12.1.0.
sysbackup for backup operations
sysdg for Data Guard operations
syskm for key management
Patching:
Centralised patching.
We can retrieve OPatch information using sqlplus query, using DBMS_QOPATCH package
SQL> select dbms_qopatch.get_opatch_lsinventory() from dual;
We can test patches on database copies, rolling patches out centrally once testing is complete.
New Commands
create pluggable database ...
alter pluggable database ...
drop pluggable database ...
New background processes - LREG (Listener Registration), SA (SGA Allocator), RM.
Oracle Database 12c Data Pump will allow turning off redo for the import operation (only).
$ impdp ... transform=disable_archive_logging:y
There are lots of differences!
Some of the big ones are:
- Multitenant/pluggable databases
- In Memory (12.1.0.2
- JSON support (12.1.0.2)
- Adaptive queries
- New histogram types
- SQL enhancements (match_recognize, PL/SQL in the with clause, ...)
Some of the big ones are:
- Multitenant/pluggable databases
- In Memory (12.1.0.2
- JSON support (12.1.0.2)
- Adaptive queries
- New histogram types
- SQL enhancements (match_recognize, PL/SQL in the with clause, ...)
Subscribe to:
Posts (Atom)